-
머신러닝과 데이터 전처리 - 초보자를 위한 친절한 가이드🐍 Python 2025. 1. 30. 18:50728x90
1. 머신러닝이란?
머신러닝(Machine Learning)은 데이터를 이용하여 패턴을 학습하고, 이를 통해 예측을 수행하는 인공지능 기술입니다. 우리가 실생활에서 머신러닝을 만나는 사례는 다음과 같습니다.
- 손으로 쓴 우편번호 자동 인식 (우체국 자동 시스템)
- 의료 영상에서 종양 여부 판단 (AI 진단)
- 신용카드 부정 사용 감지 (이상 거래 탐지)
- 블로그 글의 주제 자동 분류 (텍스트 분류)
- 고객을 취향이 비슷한 그룹으로 묶기 (추천 시스템)
이처럼 머신러닝은 다양한 분야에서 활용되고 있으며, 우리가 해결하고자 하는 문제를 정의하고 적절한 데이터를 확보하는 것이 가장 중요합니다.
2. 문제와 데이터 이해하기
머신러닝을 적용하기 전에 다음과 같은 질문을 던져야 합니다.
- 가지고 있는 데이터가 문제를 해결하는 데 충분한 정보를 포함하고 있는가?
- 가장 적합한 머신러닝 기법은 무엇인가?
- 데이터의 품질은 어떠한가? (결측값, 이상치 등)
- 모델의 성능을 어떻게 평가할 것인가?
3. 머신러닝의 주요 개념
머신러닝은 크게 지도 학습(Supervised Learning)과 비지도 학습(Unsupervised Learning)으로 나뉩니다.

지도 학습 (Supervised Learning)
지도 학습에서는 정답(Label)이 있는 데이터를 이용하여 모델을 학습시킵니다.
예제: 붓꽃(Iris) 데이터셋을 이용한 품종 분류
- 꽃잎과 꽃받침의 길이/넓이 데이터를 입력으로 사용합니다.
- 각 데이터에 해당하는 꽃의 품종(Setosa, Versicolor, Virginica)을 정답(Label)으로 사용합니다.
- 새로운 꽃 데이터가 입력되었을 때, 해당 꽃의 품종을 예측할 수 있도록 학습합니다.
비지도 학습 (Unsupervised Learning)
비지도 학습에서는 정답(Label) 없이 데이터만을 가지고 숨겨진 패턴을 찾습니다.
예제: 고객 군집화(Clustering)
- 고객의 구매 데이터를 분석하여 비슷한 소비 패턴을 가진 그룹으로 분류합니다.
- 이를 통해 맞춤형 마케팅 전략을 수립할 수 있습니다.
4. 데이터 전처리 (Data Preprocessing)
모델을 학습시키기 전에 데이터 전처리를 수행해야 합니다. 데이터 전처리는 머신러닝 성능을 향상시키는 중요한 과정입니다.

4.1. 데이터 정리
데이터 정리는 머신러닝 모델의 성능을 높이기 위한 필수적인 과정으로, 정확한 분석을 위해 데이터를 깨끗하고 체계적으로 정리하는 과정입니다. 데이터 정리는 크게 결측값 처리, 이상치 제거, 중복 데이터 제거 등의 작업을 포함합니다.
4.1.1. 결측값 처리 (Handling Missing Values)
결측값(missing values)은 특정 컬럼에 값이 누락된 경우를 의미합니다. 결측값을 방치하면 모델의 정확도가 저하될 수 있으므로 적절한 처리 방법이 필요합니다.
우선은 NaN 파일이 있는지 확인을 진행 해 줍니다.

- 삭제 방법: 결측값이 많은 경우 해당 행(row) 또는 열(column)을 삭제합니다.

- 평균, 중앙값 대체: 연속형 데이터는 평균(mean) 또는 중앙값(median)으로 채웁니다.

- 모드 대체: 범주형 데이터는 가장 많이 등장한 값(mode)으로 채웁니다.
- 예측 기법 활용: 머신러닝 모델을 활용하여 결측값을 예측할 수도 있습니다.
import pandas as pd from sklearn.impute import SimpleImputer # 데이터 생성 data = {'Age': [25, 30, None, 35, 40], 'Salary': [50000, 60000, 55000, None, 70000]} df = pd.DataFrame(data) # 평균값으로 결측값 대체 imputer = SimpleImputer(strategy='mean') df.iloc[:, :] = imputer.fit_transform(df) print(df)4.1.2. 이상치 제거 (Handling Outliers)
이상치(outliers)는 데이터에서 정상적인 범위를 벗어난 값으로, 모델의 성능을 저하시킬 수 있습니다. 이상치를 탐지하고 제거하는 방법은 다음과 같습니다.
- IQR(사분위수 범위) 방법: 데이터의 1사분위(Q1)와 3사분위(Q3)를 이용하여 이상치를 탐지합니다.
- Z-Score 방법: 평균에서 표준편차의 특정 배수 이상 벗어난 값을 이상치로 간주합니다.
import numpy as np # IQR 방법을 활용한 이상치 제거 Q1 = df.quantile(0.25) Q3 = df.quantile(0.75) IQR = Q3 - Q1 # 이상치 제거 df_clean = df[~((df < (Q1 - 1.5 * IQR)) | (df > (Q3 + 1.5 * IQR))).any(axis=1)] print(df_clean)4.1.3. 중복 데이터 제거 (Removing Duplicates)
데이터셋에는 같은 값이 여러 번 반복되는 경우가 있을 수 있습니다. 중복 데이터를 제거하여 데이터의 품질을 개선할 수 있습니다.
# 중복된 행 제거 df.drop_duplicates(inplace=True) print(df)4.2.데이터 변환 (Data Transformation)


4.2.1. 정규화 (Normalization)
정규화는 데이터를 0과 1 사이의 값으로 변환하는 과정입니다. 머신러닝 모델의 성능을 향상시키기 위해 데이터를 일정한 범위로 조정합니다.
from sklearn.preprocessing import MinMaxScaler import numpy as np # 데이터 생성 data = np.array([[10], [20], [30], [40], [50]]) # 정규화 적용 scaler = MinMaxScaler() normalized_data = scaler.fit_transform(data) print(normalized_data)4.2.2. 표준화 (Standardization)
표준화는 데이터를 평균이 0, 표준편차가 1이 되도록 변환하는 과정입니다. 이는 데이터가 정규 분포를 따를 때 효과적입니다.

from sklearn.preprocessing import StandardScaler import numpy as np # 데이터 생성 data = np.array([[10], [20], [30], [40], [50]]) # 표준화 적용 scaler = StandardScaler() standardized_data = scaler.fit_transform(data) print(standardized_data)4.2.3. 범주형 데이터 변환 (Categorical Data Encoding)
머신러닝 모델은 숫자 데이터를 입력으로 받기 때문에, 텍스트 데이터를 숫자로 변환하는 과정이 필요합니다.
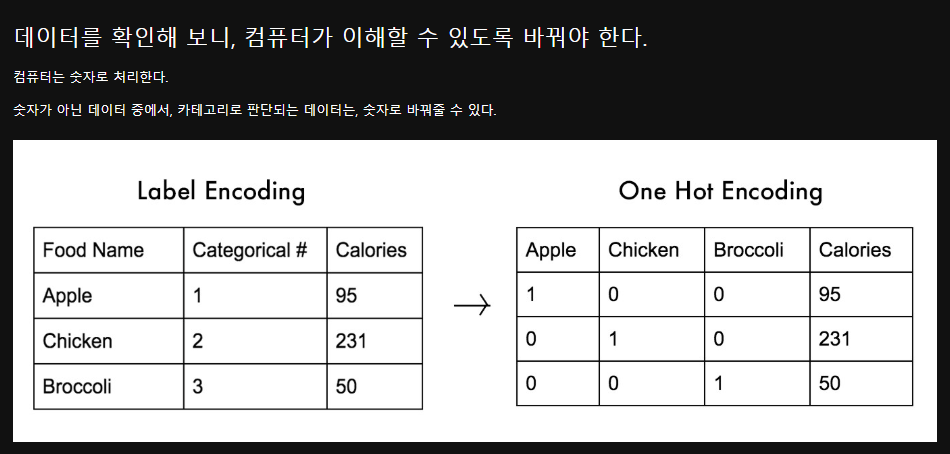
4.2.3.1. 레이블 인코딩 (Label Encoding)
레이블 인코딩은 각 범주(Category)를 고유한 정수 값으로 변환하는 방식입니다.

from sklearn.preprocessing import LabelEncoder import pandas as pd # 샘플 데이터 생성 df = pd.DataFrame({'Country': ['France', 'Germany', 'Spain', 'France', 'Spain']}) # Label Encoding 적용 label_encoder = LabelEncoder() df['Country_encoded'] = label_encoder.fit_transform(df['Country']) print(df)4.2.3.2. 원핫 인코딩 (One-Hot Encoding)
원핫 인코딩은 각 범주를 개별적인 열(Column)로 만들고, 해당하는 값만 1로 표시하는 방식입니다.

from sklearn.preprocessing import OneHotEncoder import pandas as pd # 데이터 변환 df = pd.DataFrame({'Country': ['France', 'Germany', 'Spain', 'France', 'Spain']}) # One-Hot Encoding 적용 onehot_encoder = OneHotEncoder(sparse_output=False) encoded_array = onehot_encoder.fit_transform(df[['Country']]) # 새로운 데이터프레임 생성 encoded_df = pd.DataFrame(encoded_array, columns=onehot_encoder.get_feature_names_out(['Country'])) df = pd.concat([df, encoded_df], axis=1) print(df)# 각각 문자열에 매칭되도록 , 0부터 숫자로 매긴다
#France 0
# Spain 1
# Germany 2
# 위와 같이 하니까 갯수가 적어서 그런지 학습이 잘 안된다. 그래서 워핫인코딩으로 하는것으로 하자
# 'France', 'Spain', 'Germany' 원래 있던 Country 한개의 컬럼을 3개로 늘린 후
# 'France', 'Spain', 'Germany' Age Salary
# 1 0 0 44.0 72000.0
# 0 1 0 27.0 48000.0
# 위와 같은 방식으로 모든 데이터를 늘리자
# 위와 같은 방식을 원핫 인코딩이라고 한다.
# 위와 같은 방식으로 학습을 시키니 잘 되더라
4.3. 데이터 분할
학습 데이터(train set)와 테스트 데이터(test set)로 데이터를 나눕니다.
- 일반적으로 80% 학습, 20% 테스트 비율을 사용합니다.

# 위의 화면에서 첫번째 어레이는 시험용 , 두번째 어레이는 시험용 ,
3번째 어렝는 정답지, 4번째 어레이는 시험용 정답지
5. 머신러닝 모델 학습 및 평가
데이터 전처리가 끝나면 머신러닝 모델을 학습시키고 성능을 평가합니다.
5.1. 모델 학습
from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.datasets import load_iris # 데이터 불러오기 iris = load_iris() X, y = iris.data, iris.target # 데이터 분할 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 모델 학습 model = RandomForestClassifier(n_estimators=100, random_state=42) model.fit(X_train, y_train)5.2. 모델 평가
from sklearn.metrics import accuracy_score # 예측 수행 y_pred = model.predict(X_test) # 정확도 평가 accuracy = accuracy_score(y_test, y_pred) print(f"모델 정확도: {accuracy:.2f}") 728x90
728x90'🐍 Python' 카테고리의 다른 글
KK-최근접 이웃 (KNN, K-Nearest Neighbors) 알고리즘: 개념부터 실습까지 (0) 2025.01.31 리니어리그레션 (Linear Regression) 완벽 이해: 경력과 연봉의 관계 예측하기- Prediction (예측) (0) 2025.01.30 파이썬 그래프 관련 함수 정리 (Matplotlib 중심) (0) 2025.01.29 로지스틱 회귀 (Logistic Regression): 머신러닝 이진 분류 알고리즘의 이해와 실습 (0) 2025.01.27 파이썬 플롯(Python Plot) 완벽 가이드 (0) 2025.01.24