🐍 Python/🐍 인공지능
KK-최근접 이웃 (KNN, K-Nearest Neighbors) 알고리즘: 개념부터 실습까지
itstory(Booho)
2025. 1. 31. 11:16
728x90
1️⃣ K-최근접 이웃(KNN)이란?📌 KNN의 핵심 개념
- 비모수적(Non-parametric) 모델: 사전에 학습을 하지 않고, 데이터가 들어올 때마다 계산하여 예측.
- 거리 기반 분류: 새로운 데이터가 들어왔을 때, 가장 가까운 K개의 데이터 포인트를 찾아 다수결 투표로 분류 결정.
- K 값의 설정: K 값이 크면 과적합(overfitting)을 방지하지만, 너무 크면 정확도가 떨어질 수 있음.


📌 KNN의 활용 사례
- 질병 예측 (환자의 증상이 기존 환자와 얼마나 유사한가?)
- 추천 시스템 (비슷한 취향의 사용자가 좋아하는 콘텐츠 추천)
- 이미지 분류 (손글씨 숫자 인식 등)
2️⃣ KNN의 동작 원리
- 데이터 포인트 간의 거리 계산
- 가장 일반적으로 사용되는 거리는 유클리드 거리(Euclidean Distance)
- 유클리드 거리 공식:
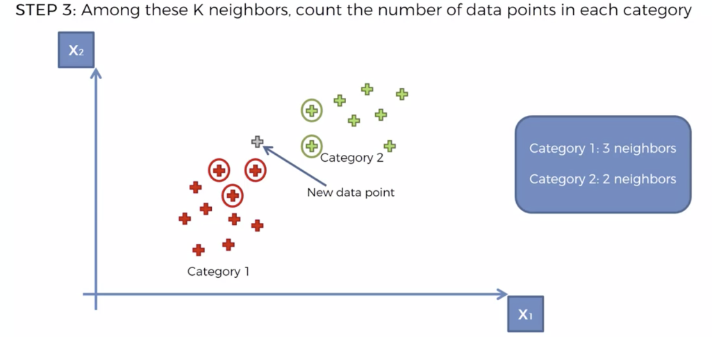
- K개의 최근접 이웃 찾기
- 데이터셋 내에서 가장 가까운 K개의 포인트를 선택
- 다수결 투표(Majority Vote)로 분류 결정
- 선택된 K개의 이웃 중 가장 많이 등장하는 클래스로 예측



📌 K 값 선택의 중요성
- K가 너무 작으면 과적합(overfitting) 문제가 발생할 수 있음.
- K가 너무 크면 일반화(generalization) 성능이 저하될 수 있음.
- 일반적으로 홀수 K를 사용하여 동점 상황을 방지
3️⃣ 실습: KNN을 활용한 광고 클릭 예측
- 데이터셋: Social_Network_Ads.csv
- 목표: 사용자의 나이와 연봉을 기반으로 광고 클릭 여부 예측
📌 1. 데이터 로드 및 전처리
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import confusion_matrix, accuracy_score
# 데이터 로드
dataset = pd.read_csv('Social_Network_Ads.csv')
# 독립변수(X)와 종속변수(y) 분리
X = dataset[['Age', 'EstimatedSalary']].values
y = dataset['Purchased'].values
# 훈련 데이터와 테스트 데이터로 분리 (80:20 비율)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 피처 스케일링 (표준화)
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)✅ 데이터를 전처리하고, 훈련 데이터와 테스트 데이터로 나눕니다.
📌 2. KNN 모델 학습 및 예측
# KNN 모델 생성 (K=5)
classifier = KNeighborsClassifier(n_neighbors=5, metric='minkowski', p=2)
classifier.fit(X_train, y_train)✅ K=5로 설정하여 모델을 학습시킵니다.
# 예측 수행
y_pred = classifier.predict(X_test)
✅ 테스트 데이터를 기반으로 예측값을 도출합니다.
📌 3. 모델 평가: 혼동 행렬 및 정확도 분석
# 혼동 행렬 및 정확도 계산
cm = confusion_matrix(y_test, y_pred)
accuracy = accuracy_score(y_test, y_pred)
print("Confusion Matrix:")
print(cm)
print(f"Accuracy: {accuracy:.2f}")✅ 혼동 행렬(Confusion Matrix)과 정확도를 출력하여 모델 성능을 평가합니다.
4️⃣ 평가 및 K 값 선택
| 실제 값 → 예측 값 ↓ | 0 (미구매) | 1 (구매) |
| 0 (미구매) | TN (True Negative) | FP (False Positive) |
| 1 (구매) | FN (False Negative) | TP (True Positive) |
📌 정확도 분석
- 정확도(Accuracy): 전체 예측 중 맞춘 비율
- 정밀도(Precision), 재현율(Recall), F1-score 도출 가능
📌 최적의 K 찾기
accuracies = []
k_values = range(1, 21)
for k in k_values:
classifier = KNeighborsClassifier(n_neighbors=k)
classifier.fit(X_train, y_train)
y_pred = classifier.predict(X_test)
accuracies.append(accuracy_score(y_test, y_pred))
# 그래프 시각화
plt.plot(k_values, accuracies, marker='o')
plt.xlabel('K 값')
plt.ylabel('정확도')
plt.title('K 값에 따른 정확도 변화')
plt.show()✅ 위 그래프를 통해 최적의 K 값을 찾아볼 수 있습니다.
5️⃣ 결론 및 요약
- KNN은 거리 기반으로 분류하는 간단하면서도 강력한 알고리즘입니다.
- K 값의 선택이 모델 성능에 중요한 영향을 미칩니다.
- 최적의 K 값을 찾기 위해 교차 검증(Cross-validation) 또는 그래프 분석을 활용할 수 있습니다.
- 과적합을 방지하기 위해 K 값을 적절히 조정해야 합니다.

728x90
반응형