데이터를 분류하는 첫 번째 선
데이터를 효과적으로 분류하기 위해 우리는 특정 기준을 설정하고 이를 바탕으로 데이터를 나눠야 합니다. 디시전 트리는 이러한 분류 과정을 시각적으로 표현하는 가장 직관적인 방법 중 하나입니다.
우리는 데이터를 분류할 때, 가장 먼저 첫 번째 분할 기준을 결정해야 합니다. 예를 들어, 아래와 같은 데이터가 있다고 가정해 봅시다.
- 특정 데이터의 값을 기준으로 그룹을 나눈다.
- 첫 번째 기준을 설정하여 데이터를 상위 그룹과 하위 그룹으로 분할한다.
이제 이 과정을 단계별로 살펴보겠습니다.
첫 번째 선: 데이터의 첫 번째 분할
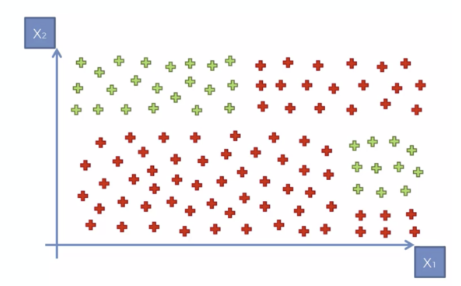
먼저, 데이터를 분석하여 어떤 기준으로 분할할 것인지 결정해야 합니다. 일반적으로 Y축 값(예: 특정 값이 60보다 큰가 작은가?)**을 기준으로 데이터를 나누어볼 수 있습니다.
첫 번째 분할 기준
- Y축을 기준으로 데이터를 나누기
- Y값이 60보다 큰 데이터는 한 그룹.
- Y값이 60보다 작은 데이터는 다른 그룹.
이렇게 데이터를 분할하면 데이터의 큰 구조를 이해하는 데 도움이 됩니다. 하지만 여기서 끝나는 것이 아닙니다. 우리가 원하는 것은 보다 세밀한 분류이므로, 추가적인 분할을 진행해야 합니다.
두 번째 선: 세부적인 분할
데이터를 더 잘 구분하기 위해, 한 번 더 분할 기준을 설정합니다. 이번에는 X축 값을 활용하여 그룹을 나눕니다.
두 번째 분할 기준
- X축을 기준으로 데이터를 나누기
- 특정 X값보다 큰 데이터는 한 그룹.
- 특정 X값보다 작은 데이터는 다른 그룹.
이처럼 데이터를 여러 번 나누면 점점 더 정확한 분류가 가능해집니다.
디시전 트리의 구조와 분할 과정
디시전 트리는 기본적으로 X축과 Y축을 번갈아 가면서 데이터를 나누는 방식을 따릅니다. 처음에는 큰 범위에서 시작하여, 점차적으로 작은 영역으로 나누어 가는 방식입니다.
하지만 이러한 과정이 계속 반복되면 어떻게 될까요?
- 데이터를 계속해서 세분화하면 너무 많은 분할이 발생할 수 있습니다.
- 경우에 따라 너무 많은 노드가 생성되어 과적합(Overfitting) 문제가 발생할 수도 있습니다.
- 따라서 적절한 수준에서 가지치기(Pruning)를 진행해야 합니다.
디시전 트리는 이러한 규칙에 따라 최적의 분할을 찾아가는 알고리즘입니다. 사용자가 원하는 목적에 맞게 분할 기준을 설정하고 이를 조절하는 것이 중요합니다.

디시전 트리의 개념을 시각적으로 이해하기
디시전 트리는 데이터를 선으로 나누어 가는 과정이라고 할 수 있습니다. 우리가 첫 번째 선을 설정하면, 이후에는 새로운 기준을 통해 추가적인 분할을 진행할 수 있습니다.
이 과정에서 X축과 Y축을 번갈아 가면서 데이터를 나누는 방식이 핵심이 됩니다.
- 첫 번째 기준에서 데이터를 나눈다.
- 각 그룹 내에서 새로운 기준을 적용해 또 나눈다.
- 이를 반복하며 최적의 분류를 찾아간다.
이처럼 디시전 트리는 계속해서 데이터를 쪼개는 방식으로 작동합니다. 하지만 너무 많은 분할이 이루어지면 모델이 과적합될 수 있기 때문에, 적절한 가지치기를 통해 이를 조절하는 것이 중요합니다.
디시전 트리의 예제: 신규 데이터 분류 과정
디시전 트리는 신규 데이터가 주어졌을 때 해당 데이터가 어느 그룹에 속하는지를 결정하는 데에도 사용됩니다.
예를 들어, 새로운 데이터가 주어졌다고 가정해봅시다.
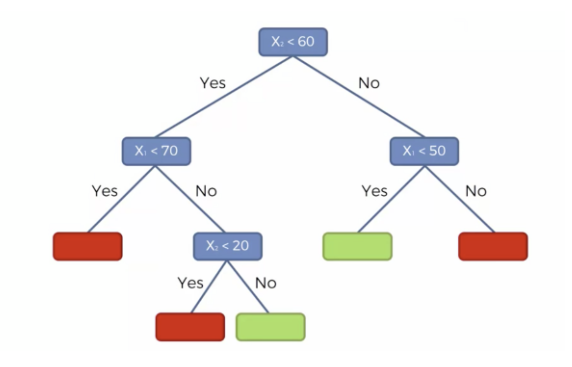
- 첫 번째 기준인 Y축 60을 확인 → 60보다 작은가, 큰가?
- 그 후, X축 기준으로 추가적인 분할 진행 → X값이 특정 값보다 큰가, 작은가?
- 계속해서 분할하며 최종적으로 해당 데이터가 속할 그룹을 결정
이 과정을 통해 신규 데이터가 기존 분류된 데이터 중 어디에 속하는지를 예측할 수 있습니다.

디시전 트리 모델 학습을 위한 데이터 준비
디시전 트리를 학습시키기 위해서는 적절한 데이터 준비 과정이 필요합니다.


데이터 전처리 과정
- 결측치 확인
- 데이터를 가져온 후, isna().sum() 함수를 사용하여 결측치가 있는지 확인합니다.
- 결측치가 없다면 다음 단계로 진행합니다.
- 독립변수(X)와 종속변수(Y) 설정
- 종속변수(Y) : target_column
- 독립변수(X) : age, salary 등의 컬럼을 포함
- 데이터 확인
- df.info() 및 df.describe()를 사용하여 데이터 분포를 파악합니다.
- 문자열 데이터가 포함되어 있다면 Label Encoding 또는 One-Hot Encoding을 수행해야 합니다.
- 피처 스케일링 (Feature Scaling)
- StandardScaler를 사용하여 데이터를 정규화합니다.
- scaler = StandardScaler()를 사용하여 데이터를 학습하고 fit_transform()을 이용해 변환합니다.
- 이를 통해 age와 estimated_salary 컬럼이 일정한 범위로 변환됩니다.


-
- 데이터셋 분할 및 모델 학습디시전 트리를 학습시키기 위해 먼저 데이터를 학습용(train)과 테스트용(test) 데이터로 나눕니다.이렇게 하면 학습용 데이터 80%, 테스트 데이터 20%로 나뉘며, random_state를 설정하여 재현성을 확보할 수 있습니다.
이제 학습이 완료되었습니다. 모델이 학습한 기준을 바탕으로 새로운 데이터를 분류할 준비가 되었습니다.from sklearn.tree import DecisionTreeClassifier classifier = DecisionTreeClassifier(random_state=27) classifier.fit(X_train, y_train)
이제 predictions 변수에는 테스트 데이터에 대한 예측 결과가 저장됩니다.predictions = classifier.predict(X_test)
- 데이터셋 분할 및 모델 학습디시전 트리를 학습시키기 위해 먼저 데이터를 학습용(train)과 테스트용(test) 데이터로 나눕니다.이렇게 하면 학습용 데이터 80%, 테스트 데이터 20%로 나뉘며, random_state를 설정하여 재현성을 확보할 수 있습니다.
- 예측 수행 및 검증
-
- 디시전 트리 모델 생성 및 학습

-
- 데이터셋 분리

랜덤 포레스트 모델 적용
랜덤 포레스트는 여러 개의 의사 결정 트리를 결합하여 보다 강력한 분류 성능을 제공하는 앙상블 학습 기법입니다.
랜덤 포레스트 모델 생성 및 학습
from sklearn.ensemble import RandomForestClassifier
# 랜덤 포레스트 모델 생성
classifier_rf = RandomForestClassifier(n_estimators=100, random_state=27)
classifier_rf.fit(X_train, y_train)위 코드에서는 n_estimators=100을 설정하여 100개의 트리를 학습하는 랜덤 포레스트 모델을 생성하고 학습시킵니다.
모델 예측 및 평가
# 예측 수행
y_pred_rf = classifier_rf.predict(X_test)
# 정확도 측정
accuracy_rf = accuracy_score(y_test, y_pred_rf)
print(f'랜덤 포레스트 모델 정확도: {accuracy_rf:.4f}')
# 혼동 행렬 확인
conf_matrix_rf = confusion_matrix(y_test, y_pred_rf)
print('랜덤 포레스트 혼동 행렬:\n', conf_matrix_rf)랜덤 포레스트는 다수의 의사 결정 트리를 기반으로 예측을 수행하며, 개별 트리보다 일반화 성능이 뛰어납니다. 이를 통해 데이터의 분류 정확도를 향상시킬 수 있습니다.


XGBoost 모델 적용
XGBoost는 강력한 부스팅 기법을 활용한 머신러닝 모델로, 회귀 및 분류 문제에 널리 사용됩니다.
XGBoost 모델 생성 및 학습
from xgboost import XGBClassifier
# XGBoost 모델 생성
classifier_xgb = XGBClassifier(n_estimators=100, learning_rate=0.1, random_state=27)
classifier_xgb.fit(X_train, y_train)모델 예측 및 평가
# 예측 수행
y_pred_xgb = classifier_xgb.predict(X_test)
# 정확도 측정
accuracy_xgb = accuracy_score(y_test, y_pred_xgb)
print(f'XGBoost 모델 정확도: {accuracy_xgb:.4f}')
# 혼동 행렬 확인
conf_matrix_xgb = confusion_matrix(y_test, y_pred_xgb)
print('XGBoost 혼동 행렬:\n', conf_matrix_xgb)XGBoost는 랜덤 포레스트보다 성능이 뛰어난 경우가 많으며, 다양한 하이퍼파라미터를 조정하여 최적의 성능을 낼 수 있습니다.
하이퍼파라미터 튜닝
classifier_xgb_tuned = XGBClassifier(n_estimators=200, learning_rate=0.05, max_depth=5, random_state=27)
classifier_xgb_tuned.fit(X_train, y_train)
마무리: 여러분이 직접 결정하는 데이터 분할
디시전 트리, 랜덤 포레스트, XGBoost는 기본적으로 데이터를 잘 분류하기 위한 모델입니다.
- 디시전 트리는 데이터를 반복적으로 나누며 분류를 수행
- 랜덤 포레스트는 여러 개의 트리를 결합하여 더 나은 성능을 제공
- XGBoost는 부스팅 기법을 활용하여 고성능의 모델을 제공
- 각 모델은 데이터에 따라 다르게 작동하며 최적의 모델을 찾아야 함
'🐍 Python' 카테고리의 다른 글
| K-Means Clustering 실습 및 이론 정리 (0) | 2025.02.01 |
|---|---|
| Unsupervised Learning과 K-Means Clustering (0) | 2025.01.31 |
| 서포트 벡터 머신 (SVM, Support Vector Machine): 개념부터 실습까지 (0) | 2025.01.31 |
| KK-최근접 이웃 (KNN, K-Nearest Neighbors) 알고리즘: 개념부터 실습까지 (0) | 2025.01.31 |
| 리니어리그레션 (Linear Regression) 완벽 이해: 경력과 연봉의 관계 예측하기- Prediction (예측) (0) | 2025.01.30 |